
테스트 환경: python 3.10.6
cx-Oracle 8.3.0
windows
디비 모니터링을 위해 디비가 아닌 파일로 이벤트 정보를 파일로 저장하게 만들었지만 정보를 이용 하기 힘들어 디비에 넣어서 확인을 해보기로 했습니다.
파일은 mon_resptime_YYYYMMDD.out 이런 형식으로 일별로 파일이 생성이 되고
TIME EVENT WAITS1 WAITS2 TIME1 TIME2
----------------- ----------------------- --------------- --------------- ----------------- -----------------
22/01/01 00:00:06 db file parallel write 458317874 58015249 124183909927 38364581669
22/01/01 00:00:06 db file sequential read 6872621403 16428512088 2846508128410 7571268385829
22/01/01 00:00:06 log file parallel write 341380914 368987859 97651008610 127148961549
22/01/01 00:00:06 log file sync 225688275 219796067 1674751565680 164672273498
Sat Jan 1 00:00:16 KST 2022
TIME EVENT WAITS1 WAITS2 TIME1 TIME2
----------------- ----------------------- --------------- --------------- ----------------- -----------------
22/01/01 00:00:17 db file parallel write 458318047 58015258 124183951957 38364584779
22/01/01 00:00:17 db file sequential read 6872621605 16428531847 2846508227222 7571273801222
22/01/01 00:00:17 log file parallel write 341381244 368989245 97651087765 127149294755
22/01/01 00:00:17 log file sync 225688324 219797377 1674751578801 164672703800
위와 같이 내용이 저장 되는데 문제는 중간에 날짜와 컬럼 정보들로 인해 이대로 데이터를 넣기가 힘든 점입니다.
다른 여러 방법이 있겠지만 전 Python 을 이용해 해당 파일을 수정 하고 디비에 insert 를 해보기로 했습니다.
우선 해당 파일에서 불필요한 요소 세가지가 있습니다.
1. Sat Jan 1 00:00:16 KST 2022
2. TIME EVENT WAITS1 WAITS2 TIME1 TIME2
3. ----------------- ----------------------- --------------- --------------- ----------------- -----------------
테이블에 데이터를 넣을 때 필요 없는 데이터를 지울수 있는 코드를 만들었습니다.
파이썬 들여쓰기로 코드의 영역을 구분 하기 때문에 주의를 해야 합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import os
input_dir = "D:\\temp\\target\\" # 입력 파일이 있는 디렉토리
output_dir = "D:\\temp\\output\\" # 출력 파일을 저장할 디렉토리
for filename in os.listdir(input_dir):
if filename.startswith("mon_resptime_") and filename.endswith(".out"):
input_path = os.path.join(input_dir, filename)
output_path = os.path.join(output_dir, filename.replace("mon_resptime_", "c_mon_resptime_"))
# 파일 처리 코드를 작성합니다.
with open(input_path, "r") as f_in, open(output_path, "w") as f_out:
for line in f_in:
if line[0].isdigit():
# 입력 파일에서 라인을 읽어서 처리한 후 출력 파일에 씁니다.
# 예시로는 라인 그대로 출력하는 코드를 작성했습니다.
f_out.write(line)
print(f"파일 저장 완료 {output_path}")
|
cs |
이 코드에서는 Python 기본 라이브러리인 os 를 이용 했습니다.
우선 작업을 할 디렉토리를 저장 할 변수 두개를 선언 했습니다.
input_dir : 작업 대상 파일이 있는 위치
output_dir : 데이터를 변형 후 저장 할 위치
os.listdir 함수는 디렉토리 안을 조회 하는 함수 입니다. 이 함수를 이용해 조회된 리스트를 for 문을 이용해 반복 처리를 합니다.
그리고 if 문으로 작업 할 파일만 필터링 합니다.
if filename.startswith("mon_resptime_") and filename.endswith(".out"):
파일의 시작 명칭과 마지막 확장자가 일치 할 경우에 참이 되도록 하고
input_path = os.path.join(input_dir, filename)
os.path.join 함수를 이용해 작업 대상 디렉토리와 파일명을 합쳐 절대 위치를 만들어 input_path 에 저장을 합니다.
output_path = os.path.join(output_dir, filename.replace("mon_resptime_", "c_mon_resptime_"))
filename.replace 로 파일명을 변경 하고 output 파일을 저장할 위치를 변수에 저장 합니다.
with open(input_path, "r") as f_in, open(output_path, "w") as f_out:
작업이 완료 후 자동으로 파일을 close 할 수 있게 with 문을 이용해 작업 대상 파일은 "r" 로 출력 대상 파일은 "w" 로 쓰기 로 파일을 오픈 합니다.
그리고 파일을 for 문을 이용해 라인 별로 읽어 들입니다.
for line in f_in:
사용 할 데이터가 있는 정보만 추출하기 위해 라인의 첫번째 글자가 숫자로 된 경우만 데이터를 저장 하도록 조건을 만듭니다.
if line[0].isdigit():
사용 하는 방법은 간단합니다. 파일에 저장 하고 실행만 하면 됩니다.
D 드라이브의 볼륨에는 이름이 없습니다.
볼륨 일련 번호: AA6F-62FC
d:\temp 디렉터리
2023-04-10 오후 02:14 <DIR> .
2023-04-10 오후 02:14 <DIR> ..
2023-04-10 오후 02:22 874 file_create.py
2023-04-19 오후 01:20 <DIR> output
2023-04-10 오후 01:48 <DIR> target
1개 파일 874 바이트
4개 디렉터리 39,718,293,504 바이트 남음
d:\temp>python file_create.py
파일 저장 완료 D:\temp\output\c_mon_resptime_20220101.out
파일 저장 완료 D:\temp\output\c_mon_resptime_20220102.out
파일 저장 완료 D:\temp\output\c_mon_resptime_20220103.out
파일 저장 완료 D:\temp\output\c_mon_resptime_20220104.out
파일 저장 완료 D:\temp\output\c_mon_resptime_20220105.out
파일 저장 완료 D:\temp\output\c_mon_resptime_20220106.out
파일 저장 완료 D:\temp\output\c_mon_resptime_20220107.out
파일 저장 완료 D:\temp\output\c_mon_resptime_20220108.out
파일 저장 완료 D:\temp\output\c_mon_resptime_20220109.out
파일 저장 완료 D:\temp\output\c_mon_resptime_20220110.out
파일 저장 완료 D:\temp\output\c_mon_resptime_20220111.out
파일 저장 완료 D:\temp\output\c_mon_resptime_20220112.out
....
d:\temp>
다음은 파일을 insert 하는 코드 입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
import os
import re
import cx_Oracle
# 데이터베이스 연결 정보
conn = cx_Oracle.connect("db_user/db_user_pw@tns_name") # Oracle 접속
input_dir = "D:\\temp\\output\\" # 입력 파일이 있는 디렉토리
for filename in os.listdir(input_dir): # For 문으로 디렉토리 안에 있는 파일을 하나씩 검색 한다.
print(f"file insert 시작 {filename}")
if filename.startswith("c_mon_resptime_") and filename.endswith(".out"): # 원하는 파일을 지정 하기 위해 시작과 끝 확장자 부분을 명시 해준다.
input_path = os.path.join(input_dir, filename) # 디렉토리 위치와 필터링한 파일을 조합 절대위치를 만들어 변수에 지정
with open(input_path, "r") as f: # 파일을 오픈
data = [] # 딕셔너리 변수 생성
for line in f: # 읽어 들인 파일을 라인 별로 for 문을 이용해 정재 한다.
match = re.match(r'^(\d{2}\/\d{2}\/\d{2}\s+\d{2}:\d{2}:\d{2})\s+(.+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)$', line) # 데이터를 컬럼에 맞게 넣기 위해 정규식으로 분해
if match: # 분리된 순서 대로 변수에 담는다.
time = match.group(1)
event = match.group(2)
waits1 = match.group(3)
waits2 = match.group(4)
time1 = match.group(5)
time2 = match.group(6)
# 데이터베이스에 삽입할 데이터를 묶어서 리스트에 추가
data.append((time, event, waits1, waits2, time1, time2))
else:
print("No match")
# 데이터베이스에 삽입
cur = conn.cursor() # 커서 오픈
cur.executemany( # Batch insert 를 위한 함수를 이용
"INSERT INTO resptime_hist (TIME, EVENT, WAITS1, WAITS2, TIME1, TIME2) VALUES (to_date(:1,'yy/mm/dd hh24:mi:ss'), :2, :3, :4, :5, :6)", data)
conn.commit() # 완료 후 커밋
cur.close() # 커서 닫기
print(f"file insert 완료 {filename}")
# 연결 종료
conn.close()
|
cs |
여기서 추가로 사용된 라이브러리는 정규식을 위한 re , 오라클 디비 사용을 위한 cx_Oracle 입니다.
최근 python-oracledb 로 명칭이 변경 되었지만 일단 제가 설치한 버전명으로 사용하겠습니다.
cx_Oracle 의 경우 pip 를 이용해 추가로 라이브러리를 설치를 해야 합니다.
conn = cx_Oracle.connect("db_user/db_user_pw@tns_name")
오라클에 접속을 하기 위한 함수 입니다. 다양한 접속 방법을 제공 하지만 저는 TNS 를 이용해 접속을 하였습니다.
re.match 함수와 함께 사용된 정규 표현식은 다음과 같은 의미입니다.
^(\d{2}\/\d{2}\/\d{2}\s+\d{2}:\d{2}:\d{2}): 날짜와 시간을 추출하는데 사용되며, 날짜는 MM/DD/YY 형식, 시간은 HH:MM:SS 형식입니다.
\s+(.+): 이벤트 이름을 추출하는데 사용되며, 공백 이후의 모든 문자열을 추출합니다.
\s+(\d+): waits1 값을 추출하는데 사용되며, 숫자 하나 이상의 값에 매칭됩니다.
\s+(\d+): waits2 값을 추출하는데 사용되며, 숫자 하나 이상의 값에 매칭됩니다.
\s+(\d+)\s+(\d+): time1과 time2 값을 추출하는데 사용되며, 각각 숫자 하나 이상의 값에 매칭됩니다.
분리된 데이터는 딕셔너리에 저장을 하고
data.append((time, event, waits1, waits2, time1, time2))
커서를 오픈 후
cur = conn.cursor()
딕셔너리 변수에 담긴 데이터를 cur.executemany 함수를 이용해 한번에 insert 후 commit 을 합니다.
파일 하나가 insert 가 끝이 나면 cur.close() 으로 커서를 종료 하고
모든 파일이 insert 가 완료 되면 conn.close() 로 접속을 종료 합니다.
실행을 하는 것은 위의 코드 처럼 저장을 하고 실행을 시키면 됩니다.
d:\temp>dir
D 드라이브의 볼륨에는 이름이 없습니다.
볼륨 일련 번호: AA6F-62FC
d:\temp 디렉터리
2023-04-19 오후 03:16 <DIR> .
2023-04-19 오후 03:16 <DIR> ..
2023-04-19 오후 01:30 945 file_create.py
2023-04-19 오후 03:16 3,154 file_insert.py
2023-04-19 오후 01:30 <DIR> output
2023-04-10 오후 01:48 <DIR> target
2개 파일 4,099 바이트
4개 디렉터리 39,645,540,352 바이트 남음
d:\temp>
d:\temp>python file_insert.py
file insert 시작 c_mon_resptime_20220101.out
file insert 완료 c_mon_resptime_20220101.out
file insert 시작 c_mon_resptime_20220102.out
file insert 완료 c_mon_resptime_20220102.out
file insert 시작 c_mon_resptime_20220103.out
file insert 완료 c_mon_resptime_20220103.out
....
file insert 완료 c_mon_resptime_20220121.out
file insert 시작 c_mon_resptime_20220122.out
file insert 완료 c_mon_resptime_20220122.out
file insert 시작 c_mon_resptime_20220123.out
file insert 완료 c_mon_resptime_20220123.out
file insert 시작 c_mon_resptime_20220124.out
file insert 완료 c_mon_resptime_20220124.out
d:\temp>
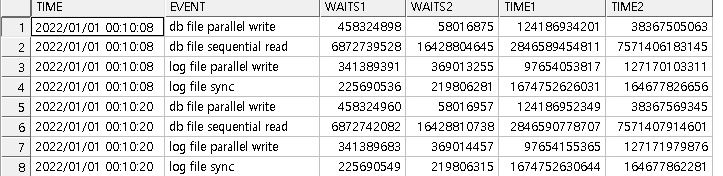
이렇게 데이터를 넣은 모습을 확인 할 수 있습니다.
서버에서 자주 사용하는 shell 이외에 다른 방법으로 최근에 사용해 보고 있는 python 에 대한 사용법을 공유해 드립니다.
좋은 내용입니다.
모니터링시에 AWR의 경우 사이즈 문제로 보관하기가 그런데 이런식으로
쌓고 리파지터리로 넘겨 놓으면 좋을 듯 합니다.